The amount of sensors in process industry is continuously increasing as they are getting faster, better and cheaper. Due to the rising amount of available data, the processing of incoming data has to be automatized in a timely and resource efficient manner. Such solution should also be easily implementable and reproducible independently of the details of the application domain. To this end, and as part of the Cogniplant project, we propose a suitable and versatile usable infrastructure, which is able to deal with Big Data in process industry on various platforms using efficient, fast and modern technologies for data gathering, processing, storing and visualization. In addition to the infrastructure implementation itself, we focus on the monitoring of infrastructure inputs and outputs, ranging from incoming data of processes and model predictions to the model performance itself to allow early interventions and actions if problems occur. Contrary to prior work, we provide an easy-to-use, easily reproducible, adaptable and configurable Big-Data management solution with a detailed implementation description that does not require expert or domain-specific knowledge.
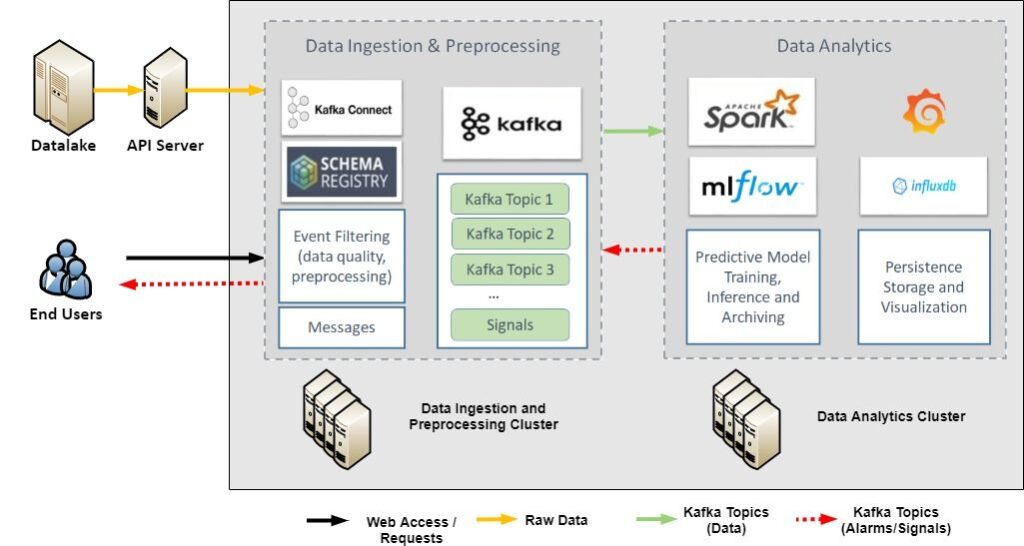
In the figure above, we provide a generic overview of the Big-Data infrastructure, including its main components as well as the information/data pipeline. The Big-Data infrastructure consists of two main nodes, that can be deployed in a single or multiple virtual machines (cluster). These two nodes serve two main functionalities, namely: a) Data Ingestion and Preprocessing, and b) Data Analytics. The “Data Ingestion and Preprocessing Cluster” node constitutes the base of the overall Big-Data infrastructure. It contains the main data management components, which correspond to the Kafka cluster, the Schema Registry and the Zookeeper. It is responsible for retrieving data from a data source, e.g using Kafka source connectors, according to the requirements of the use case. The “Data Analytics Cluster” node covers the processing of streaming data within the infrastructure. It receives the data streams generated by the “Data Ingestion and Preprocessing Cluster” node and processes it in the assigned Spark Jobs, which gather their needed data via subscriptions to a Kafka topic.